Kourosh Dini, pianista, escritor e psiquiatra, falando sobre treinar uma música mais devagar. Recomendo fortemente o canal dele para seus vídeos semanais de “recitais” de piano e sintetizador
Sim, eu também faço isso: para cumprir prazos, eu quero fazer as coisas na pressa – e aí demora mais do que se eu tivesse feito as coisas com calma.
Exemplo prático e real no mundo da Engenharia: eu recebi uma demanda de implementar um algoritmo de cálculo estrutural no programa que minha equipe e eu desenvolvemos. Eu sou Engenheiro Mecânico, e gostava bastante da área de Mecânica dos Sólidos na faculdade; mas depois segui carreira acadêmica nas Ciências Térmicas, e meus conhecimentos atrofiaram (infelizmente). Quando eu recebi a tarefa, varri o nosso código (que é bastante extenso, e inclui já uma parte de cálculo estrutural) em busca de fazer uma alteração rápida.
O problema é que eu não estava entendendo nada, e eu precisava desacelerar. Corri então para a biblioteca, li livros e diversos artigos, começando desde a Introdução, e agora posso ficar em paz e dizer: “entendo o que precisa ser feito!”.
Alterações em softwares nunca são filhas únicas. Esse tempo “perdido” lendo livros introdutórios vai ser compensando porque, quando outras alterações forem solicitadas (e vão ser), eu já entendo a teoria (e tenho diversas notas nos meus cadernos para serem consultadas), e posso partir diretamente para a implementação.
Recentemente, promovi uma grande refatoração no nosso programa, mudando nomes de variáveis internas e documentando cada função. Os nossos clientes não ligam absolutamente nada para isso, e esse mês foi aparentemente “desperdiçado” nessa tarefa lenta e árdua sem nenhum resultado concreto – mas novamente, cada nova alteração é facilitada porque o programa está mais fácil de entender.
Obviamente, como tudo na Engenharia, é uma questão de otimização de recursos. Minha personalidade que gosta de estudar tenderia e querer ler vários livros e artigos, e indo nas referências de cada um, até entender com máxima profundidade o assunto. Mas, após me sentir em paz, eu decido que o estudo é suficiente e é hora de implementar.
Fora que, ao fazer as coisas com calma, a probabilidade de fazer correto é maior – e não é isso que importa?
Eu aprendi a programar na faculdade, e nos semestres finais eu só fazia os trabalhos com cálculos implementados em computador. Ao longo de minha carreira, utilizei diferentes linguagens, técnicas, e métodos, mas a programação sempre fez parte do meu trabalho.
Se você estuda Engenharia, você precisa aprender a programar.
Quando eu comecei no meu emprego atual, eu me deparei com um desafio que eu não tinha enfrentado antes: desenvolver programas não seria apenas um meio para outro objetivo (como escrever teses ou preparar aulas), mas é o trabalho; meu papel aqui é desenvolver, manter, testar e documentar softwares de Engenharia que outros pesquisadores e pesquisadoras usam. Eu precisava subir de nível na minha habilidade.
O caminho que escolhi é o projeto Open Source Society University, que prescreve um “caminho” para cursar Ciências da Computação com apenas cursos online. Eu não tenho essa pretensão, e nem acho que é possível. O meu objetivo é trazer conceitos mais rigorosos, efetivos e eficazes do mundo do desenvolvimento de software para a Engenharia.
E já no primeiro curso, o mais básico, surpreendi-me positivamente, e agora acho que todo estudante de Engenharia deve começar o quanto antes o curso online e gratuito How to Code: Simple Data, que usa o meu novo livro preferido de programação (também online e gratuito) How to Design Programas (2 ed.)
Esse não é um curso sobre uma linguagem específica, tanto que usa uma linguagem não muito popular chamada Racket. É sobre projetar programas, como um projeto qualquer de Engenharia: com requisitos, critérios de sucesso (como você sabe que o programa está correto? Você testa todas as suas partes). É sobre seguir um método, rigoroso e sistemático. Tanto no curso quanto no livros, os autores enfatizam a importância de documentar o que você está fazendo, com muitos exemplos.
Minha dica é essa: siga esse curso, tentando fazer todos os exercícios, e então busque traduzir os conceitos na linguagem que você usa nos seus projetos (provavelmente uma das minhas recomendadas). A qualidade dos programas que eu escrevo e o meu entendimento sobre eles aumentou exponencialmente.
Se você está iniciando em uma carreira de pesquisa, você vai ter de tratar dados experimentais ou numéricos e apresentar seus resultados. Não há escapatória além de aprender a programar, e isto vale para todas as áreas; John MacFarlane, por exemplo, é professor de filosofia e um grande nerd.
Para mim, existem três linguagens básicas que você deve saber e estudar continuamente, e vou apresentar na ordem em que acho que devem ser estudadas. Também, como eu sou o Fábio, eu vou dar dicas de livros, que ainda são muito superiores a simples tutoriais para realmente aprender algo.
Python
Se você está começando, este é um excelente primeiro passo. Python é uma linguagem simultaneamente fácil de aprender e poderosa; é bastante geral, e tem bibliotecas para processamento de arquivos, interfaces web e cálculo numérico e matricial.
Eu uso Python regularmente para meus projetos de Engenharia desde 2011. No meu mestrado, criei scripts para pegar os arquivos que o sensor de pressão da minha bancada escrevia e criar gráficos de pressão x tempo para cada teste que eu havia feito. No meu doutorado, criei dois programas que resolviam as Equações de Maxwell para duas geometrias diferentes de ímãs permanentes e calculavam o campo magnético gerado por cada uma. Atualmente, mantenho alguns programas de simulação de poços de petróleo e cálculo de propriedades de óleos.
Uma boa introdução geral é este livro, enquanto este aqui é excelente e mais voltado para área de dados.
R
Você pode usar Python para praticamente qualquer tarefa, mas sempre há benefícios em conhecer mais linguagens. Bjarne Stroustrup, criador da linguagem C++, diz que um salto fundamental para alguém que sabe programar é passar de uma para duas linguagens: o conhecimento de uma alimenta o estudo da outra.
Acontece isso comigo ao estudar R, uma linguagem voltada à Estatística. Embora eu não use muito scripts em R em si, o conhecimento que tenho da linguagem me faz pensar melhor na organização das tabelas de dados, e em como posso juntar todas as simulações que faço em uma única tabela que é filtrada e transformada (e.g. calcular a média de todas as linhas da tabela mestre que correspondem a uma mesma condição de pressão) para diferentes tarefas. Esse conhecimento me acompanha mesmo quando escrevo os programas em Python.
Estes doislivros são excelentes e fundamentais para começar a estudar dados de maneira mais séria.
Julia
Julia é uma linguagem bem mais moderna que as outras, e bastante focada na rapidez de execução. Novamente: ao estudar e praticar Julia, eu posso tanto escrever scripts nessa linguagem como pensar em como acelerar meus programas em Python e R. Se você já tem um sistema que quer otimizar, sugiro fortemente aprender Julia; o ecossistema de bibliotecas está crescendo rapidamente.
O que vou falar aqui não combina muito com o Ano de Simplificar, mas vale a pena ser dito: às vezes, complicar torna a vida mais simples.
O meu trabalho envolve programar muito em Python, como vários outros pesquisadores do mundo. O editor da moda é o Visual Studio Code, que tem um visual mais minimalista e de fato é muito bom.
O problema é que apenas o editor não é suficiente para meu trabalho: eu preciso de um terminal de linha de comando e de ferramentas de controle de versão. O VS Code têm tudo isso, mas aí a sua simplicidade começa a sumir… E é aí que eu resolvi abraçar a complexidade e usar um editor mais profissional, PyCharm.
PyCharm não é um programa simples ou fácil de usar: há inúmeros painéis, menus, caixas de diálogo, atalhos. Mas agora, tudo que eu preciso está em um só programa – e aos poucos, estou aprendendo a navegar nessa complexidade e me tornando mais produtivo e eficiente no meu trabalho.
E no seu trabalho? Que passo adicional em relação à complexidade a leitora pode adotar que vai tornar a vida mais simples, na verdade? Que software/metodologia/ferramenta o leitor está com medo de abraçar pela complexidade, mas que vai facilitar a vida?
Como muitas de minhas ideias, está começou com um podcast, e especificamente sobre minha mais recente obsessão: ciência de dados.
A situação: tenho um modelo numérico que simula algum problema físico. Para um mesmo modelo, é possível fazer várias análises: com e sem alguma característica, modificando ou não alguma das equações governantes do problema. O problema: como organizar todas essas análises?
Quando vou testar alguma próxima modificação no meu modelo ou analisar a influência particular de algum parâmetro , onde vou armazenar todos os resultados, de maneira a poder referencia-los depois?
O meu modelo está encapsulado numa pasta no meu computador:
A pasta raiz tem imagens, um arquivo de sumário README, alguns arquivos de dados, arquivos de suporte para Python, e diversas subpastas:
Já falei anteriormente sobre testes, e eles estão devidamente organizados. O programa de testes que uso, pytest, cria uma pasta de cache, que aparece no topo da lista.
A pasta src contém o código fonte (neste caso, em Python). Kenneth Reitz havia me convencido de que uma pasta assim deve ter o mesmo nome da biblioteca sendo desenvolvida (neste caso, magnet3Dpolomag, como aparece em outro post), mas estesartigos me convenceram de que afinal é melhor ter uma pasta chamada src (de source code), e suas bibliotecas dentro dessa pasta, para melhor execução de testes. Os artigos científicos citados no começo deste posts também recomendam uma pasta genérica src.
A pasta results é um repositório de todos os resultados que esse modelo já gerou. Respondendo à pergunta anterior: quando quero fazer uma nova análise, o primeiro passo é criar uma nova subpasta dentro de results:
Um ponto importante dessa minha estratégia é fazer uso da interface web do GitHub, como visto acima, serve como referência online. Nas reuniões do nosso grupo de pesquisa, tenho compartilhado links para cada uma dessa subpastas junto com capturas de tela como essa, para mostrar em que estado minha pesquisa está e o que foi feito em um período. Seguindo a recomendação dos artigos citados, ponho a data no início do nome da pasta para uma ordenação temporal e para ter ideia de quando uma análise foi feita.
Cada pasta dessa armazena scripts para cálculo e processamento de dados, imagens e tabelas salvas, arquivos de referência — tudo que ajuda uma pessoa de fora (ou meu futuro eu) a entender uma parte da pesquisa usando meu modelo.
Numa organização dessa, é crucial criar um README bem feito, para evitar a confusão de abrir uma pasta cheia de arquivos soltos sem nenhuma explicação. Usando a interface web do GitHub, o README é renderizado quando se abre uma pasta, o que é muito interessante.
Conclusões
É assim que organizo minhas simulações numéricas. Ainda estou aprendendo a implementar esse método, mas ele tem me dado bastante tranquilidade, permite-me facilmente achar análises passadas, e elimina a dúvida de “por onde começar”, ao testar algo novo nos meus modelos numéricos.
Esse é um assunto que me interessa muito. Os leitores têm alguma dica?
Sempre que vou iniciar uma sessão de trabalho — em bom português, sentar para trabalhar — em algum projeto de programação ou escrita de um artigo, há uma série de ações repetitivas:
Abro o Sourcetree, para gerenciar as modificações que eu vou fazendo
Abro arquivos de referência (PDF de alguma documentação, por exemplo)
Ao longo da minha sessão, vou trabalhando, e periodicamente usando o supra-citado Sourcetree para registrar o que vou fazendo. Nesse período, invariavelmente meu celular está em modo Não perturbe e estou escutando a trilha sonora de algum filme, série ou jogo no Deezer.
Quando termino de trabalhar, por cansaço ou por ter de fazer outra atividade, também há série de atividades repetitivas:
Fecho todos os arquivos abertos no começo
Sincronizo minha versão atual do trabalho com a versão no GitHub.
Esse ciclo de abrir programas – trabalhar – fechar programas se repete algumas vezes ao longo de dia, de maneira que criei um sistema de automação dessas tarefas. Já falei aqui sobre como escrevi minha tese de maneira eficiente, onde automatizei algumas tarefas; o sistema que descrevo neste post é mais geral.
Um aviso: este post é bastante técnico e requer o uso do terminal de comando, em particular o sistema Git for Windows, que instala a shell Bash e muitos utiliários como programas nativos do Windows; para macOS e Linux, Bash e aplicativos de terminal já estão instalados. Se você se interesse por computação científica e quer aprender mais, existem muitos tutoriais disponíveis sobre como usar e configurar Bash, o meu canal preferido no YouTube para esse assunto é o do Corey Schafer. Os exemplos que vão mostrar aqui se aplicam a Windows, e minha configuração está disponível no GitHub.
Mesmo que o leitor não esteja familiarizado com nada disso, pode ler para tentar entender como eu automatizo algumas tarefas e ter ideias para facilitar a sua vida.
A base do meu sistema é um pequeno utilitário Bash chamado prm, que permite definir “procedimentos” de “começar” e “parar” um projeto.
Vamos a um exemplo prático. No momento estou trabalhando em um paper sobre perfis magnéticos para refrigeradores magnéticos. Após instalar prm usando as instruções do repositório, crio um projeto no terminal usando:
prm add pprof
pprof é uma abreviação de “paper profiles” (é assim que meu cérebro funciona). Esse comando cria dois scripts, em uma pasta padrão do prm (que pode ser mudada) abre-os no editor de texto padrão.
O primeiro script,start.sh, define o que é feito ao começar a trabalhar no projeto:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
O segundo script, stop.sh, é executado quando termino de trabalhar no projeto:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
No script acima, cf é uma função que fecha um arquivo no Emacs, que está definida em ~/.bash_profile.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
e closew é um comando que fecha janelas usando AutoHotKey:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
que é definido como um atalho na forma (dentro de .bash_profile).
alias closew="AutoHotkey path/to/closewindow.ahk"
Como toda automação, apesar de exigir um pouco de trabalho, estes hacks facilitam muito o trabalho e deixam minha mente livre para se concentrar no que é necessário. Por exemplo, quando quero começar a trabalhar no paper, abro uma janela do Git Bash e digito:
prm start pprof
e tudo fica pronto na minha frente. Mais importante que a abertura dos programas, no entendo, é o recado ao meu cérebro, quando digito o comando acima, de que é hora de começar a trabalhar no paper.
Quando é hora de parar, digito
prm stop pprof
e tudo se fecha, deixando meu computador pronto para outras tarefas.
Um de meus tópicos favoritos recentemente em podcasts e blogs é a discussão sobre usar notebooks ou scripts em contexto de análise de dados e computação numérica.
Se você mal chegou neste texto e não está entendendo nada, vamos por partes. Tudo que vou falar aqui se aplica ao meu contexto de computação numérica: usar computadores para resolver equações e modelos matemáticos e analisar e plotar os dados resultantes, usando gráficos e ferramentas estatísticas. Nesse tipo de ambiente, é comum usar esses dois tipos de ferramentas, conforme vou ilustrar.
Neste texto vou usar exemplos em Python, mas ambas as ferramentas podem ser usadas com várias linguagens de programação.
Nos notebooks Jupyter, eu escrevo códigos usando um ambiente interativo no navegador, com todos os recursos visuais que isso me permite.
Um exemplo de código Python, gráfico e notas em um notebook Jupyter, segundo meu uso
Um “caderno” em Jupyter é divido em células independentes, que podem conter código, imagens, ou texto. Quando uma célula de código é executada, ela pode gerar um resultado que é impresso na tela, na forma de um gráfico ou de mensagens de texto (ambos os usos aparecem na imagem acima). Além disso, a execução de uma célula depende de células que foram executadas antes dela, onde podem ter sido definidas variáveis e funções – mas isso não precisa seguir a ordem “de cima para baixo” de um caderno Jupyter, o que pode gerar cenários confusos. Por exemplo, suponha que eu executa todas as células nessa ordem vertical (até a última célula embaixo), e depois queira voltar e arrumar aquele gráfico mostrado ali; agora, a célula do gráfico vai ser influenciada por código que “teoricamente” foi escrito depois dela, já que os últimos blocos já foram executados. Já vamos falar sobre soluções para isso.
A outra abordagem é escrever um programa na forma de script, que é executado como uma unidade única. Embora alguns editores atuais até permitam isso, em geral não existe o conceito de células; as linhas de código em um script em Python vão sendo executadas individualmente de cima para baixo até o fim.
Um script de Python no Visual Studio Code sendo editado (parte de cima) e executado (parte de baixo)
Então, voltando à pergunta: quando uso um tipo e quando uso outro?
Em geral, começo minhas ideias de análise em um notebook, considerando que é para isso que ele foi criado. Notebooks no seu estágio inicial são caóticos; vou criando células, volto para trás, edito, testo novas ideias. À medida que descubro a melhor maneira de implementar alguma análise, começo então a documentar e organizar o caderno – aliás, a possibilidade de ter texto formatado junto com código é uma das principais vantagens de Jupyter. Quando ele fica “maduro”, ele serve como um relatório interativo, que pode ser constantemente atualizado.
Uso scripts para trabalhos mais pesados: já testei alguma ideia como um notebook, agora quero executar esse procedimento diversas vezes com diferentes condições. Usar um bom editor como o Visual Studio Code me permite usar bons atalhos e funções para escrever código mais rapidamente. Quando o script fica maduro, ele pode ser incorporado a alguma biblioteca e testado.
Os leitores já devem saber que sou um grande entusiasta de explorar melhor minha criatividade, mesmo em um trabalho científico. Faço sempre um esforço sobre-humano para não me deixar cair rotina de reuniões e preenchimento de relatórios de bolsa. Usar essas diferentes ferramentas de programação (e falar sobre elas) me permite brincar, conhecer a minha forma preferida de programar, descobrir novas maneiras de desenvolver meus projetos.
Em primeiro lugar, o que diabos é pytest e por que eu me importo com isso?
A biblioteca pytest é um pacote de testes em Python. Para que serve? Como eu sei que tenho muitos leitores na área acadêmica, acho que vou me fazer entender: você escreve seus projetos de programação em Python, para simulação numérica de algum problema físico, para processamento de dados, para automatizar alguma tarefa, para gerar gráficos etc. Você vai aumentando o seu programa até que não tem mais certeza de como uma parte conecta com outra. Você adiciona uma função inofensiva, e então percebe que outra, “aparentemente” não relacionada, parou de funcionar. Os arquivos que eram para ser gerados não o são mais. Os gráficos saem esquisitos. Os resultados numéricos não fazem sentido.
Testes, nesse contexto de programação, são funções adicionais que asseguram o funcionamento correto do código. Se uma determinada função, quando executada, deve sempre gerar um arquivo results.txt, então você escreve um teste que executa a função e assegura que esse arquivo existe. A cada modificação no seu programa, você executa seu teste; se ele falha, é sinal de que é preciso parar, avaliar e corrigir erros.
Neste ambiente acadêmico em que estou, não vejo muita ênfase sendo colocada em testar o seu código, o que é um contrassenso. Testes têm um sentido científico: se eles passam, então a hipótese de que o você programou representa a realidade se torna mais forte. Eles não são “perda de tempo”; é bem fácil escrever rapidamente um programa que não funciona.
Tudo o que vou falar aqui se baseia nessa minha experiência: um pesquisador que usa de programas em Python como uma ferramenta para produzir conhecimento científico.
Instalação e uso básico
Para aplicações acadêmicas, especialmente em Windows, a melhor maneira de usar Python é através da distribuição Anaconda. A biblioteca pytest já está incluida.
No espírito acadêmico de transparência, vou compartilhar exatamente como tenho usado pytest para melhorar minhas práticas de programação e, com isso, produzir resultados científicos mais confiáveis.
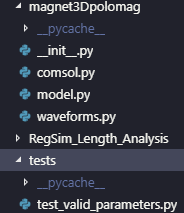
Tenho um projeto chamado magnet3Dpolomag. Não se preocupem sobre o que é, apenas entendam como minha plataforma de testes está organizada:
A propósito, esse screenshot é do Visual Studio Code
No meu diretório raiz, além de vários arquivos, existem essas duas pastas importantes: uma pasta com o pacote em Python, com seus vários módulos, e uma pasta de testes. O diretório do pacote Python é declarado como “importável” ao conter o arquivo de inicialização __init__.py. Assim, quando esse pacote é instalado, eu posso digitar simplesmente:
import magnet3Dpolomag
e tudo que estiver no arquivo __init__.pydentro da pasta magnet3Dpolomag vai ser carregado.
A convenção de testes em Python é usar nomes de arquivos que comecem com test_, e no momento eu só tenho um arquivo geral: dentro dele existem funções que testam o correto funcionamento de magnet3Dpolomag quando parâmetros válidos são fornecidos (testar se os parâmetros passados ao programa são válidos ou não é outra história).
Como um exemplo de teste, aqui está um pedaço do meu pacote: uma classe Magnet3DModel, com uma função que faz uma transformação de dados de simulações e retorna dois vetores:
import numpy as np
class Magnet3DModel:
def get_profile_data(self, ):
"""Return phi, B vectors at the central plane"""
middle_plane = self.z_profile_1q == 0
phi_middle_plane_1q = self.phi_profile_1q[middle_plane]
B_middle_plane_1q = self.B_profile_1q[middle_plane]
phi_vector = np.concatenate((phi_middle_plane_1q,
phi_middle_plane_1q + 90,
phi_middle_plane_1q + 180,
phi_middle_plane_1q + 270))
B_profile = np.concatenate((B_middle_plane_1q,
B_middle_plane_1q[::-1],
B_middle_plane_1q,
B_middle_plane_1q[::-1]))
return phi_vector, B_profile
Uma breve explicação: esse “modelo”, quando é executado, armazena uma nuvem de dados nos vetores z_profile_1q, phi_profile_1q e B_profile_1q. Para esse método em particular, estou apenas interessado nos dados que correspondem ao “plano” z_profile_1q == 0. O sufixo 1q indica que se trata de dados “no primeiro quadrante”; como os dados são periódicos, eu retorno os dados “expandidos”.
Eu quero me assegurar que, quando esse modelo é executado, essa função vai retornar esses vetores conforme esperado, com valores apenas numéricos:
import numpy as np
import magnet3Dpolomag
def test_can_access_magnetic_profile():
m = magnet3Dpolomag.Magnet3DModel()
# executa mais instruções para simular o modelo
phi_profile, B_profile = m.get_profile_data()
assert (
np.isfinite(phi_profile).all() and
np.isfinite(B_profile).all()
)
Repare na semântica do teste: ao escrever esse código, eu não tenho ideia de como get_profile_data() funciona; eu apenas sei que, quando eu executar o modelo, quero poder chamar uma função que me retorne esses vetores e que estes não tenham valores não-numéricos (que poderia surgir de algum erro). Para esse fim, eu uso a função isfinite() da biblioteca NumPy, que retorna um vetor booleano que checa exatamente isso; então, eu uso o método all() de vetores da biblioteca NumPy, que vai retornar True se todos os elementos são True.
A chave de uma função de teste é o comando assert; se o seu argumento é falso, então o programa para (ou, no caso, a função de teste falha). A biblioteca pytest tem como grande característica usar esse comando, que faz parte da linguagem Python “pura”, e reportar exatamente o que deu errado, no caso de uma falha.
Testes são executadas invocando pytest em um terminal. A partir do diretório onde é executado e varrendo os subdiretórios em todos os níveis, esse comando primeiro “descobre” os testes, arquivo que começam com test e, dentro deles, as funções e classes que começam com test_. Como quase tudo em se tratando de pytest, esse processo de descoberta de testes é configurável. A biblioteca então executa todos as funções e métodos de teste e reporta, de maneira muito inteligente, os testes que passaram e os que falharam.
Este exemplo pode parecer meio tolo, então quero enfatizar o grande propósito dessa minha discussão: escrever testes me ajuda a entender um código em Python que o meu de anos atrás escreveu, e me faz pensar sobre o que ele deve fazer.
Além disso, eu não vou estar nesse laboratório para sempre, e estes programas que eu crio para auxiliar no nosso projeto ficarão de legado para a minha equipe. Cada hora gasta trabalhando numa plataforma de testes pode não gerar resultados práticos agora, mas tem consequências futuras. Os financiadores do meu projeto atual não poderiam se importar menos se o meu código está bem testado, e talvez até achem que eu deveria estar fazendo outra coisa; mas aposto que eles ficam felizes quando a próxima pessoa que trabalhar nisso (eu mesmo eu, daqui a algumas semanas) não perder dias de trabalho tentando resolver um problema que poderia ter sido solucionando mais rapidamente executando a plataforma de testes e vendo qual parte do sistema está defeituosa.
Anteriormente escrevi que um das grandes sacadas de pytest é “turbinar” o comando `assert`. Outra grande sacada é o uso de *fixtures*: funções que auxiliam os testes. Não quero nesse post fornecer um tutorial de Python ou mesmo de pytest; quero apenas [documentar de maneira resumida como estou *aprendendo*][show] a escrever testes e motivar pesquisadores a fazer o mesmo. Além da documentação da biblioteca, [*Python Testing with pytest*][pytestbook] é bem bom. No exemplo que usei acima, eu apresentei uma função de teste que simula a execução do modelo e confere alguns dados gerados por ele. E se, com base na mesma execução do modelo, eu queira testar outras condições, como outros vetores e matrizes gerados, arquivos que devem ser gravados, parâmetros que devem ser armazenados? Esse é um exemplo clássico de *fixture*: uma função que não é um teste, mas que é executada antes dos testes, e que passa informações “compartilhadas” entre eles. Além disso, é possível repetir o mesmo teste várias vezes, checando por diferentes “coisas”. Por exemplo:
import numpy as np
import magnet3Dpolomag
import pytest
import math
@pytest.fixture(scope='module')
def run_model():
m = magnet3Dpolomag.Magnet3DModel()
m.run()
return m
def test_can_access_magnetic_profile(run_model):
m = run_model
# executa mais instruções para simular o modelo
phi_profile, B_profile = m.get_profile_data()
assert (
np.isfinite(phi_profile).all() and
np.isfinite(B_profile).all()
)
@pytest.mark.parametrize(
'result',
[
"Demagnetized fraction[%]",
"Saturated fraction[%]",
"V_gap[l]",
"V_magnet[l]",
"V_demag[l]",
"V_magnetic_steel[l]",
"V_sat_magnetic_steel[l]",
"V_stator[l]",
"V_rotor[l]"
]
)
def test_access_results(self, result, run_model):
m = run_model
r = m.get_results_series()[result]
assert ( (math.isfinite(r)) and (r >= 0))
A função no início é uma fixture que simplesmente cria e executa o meu modelo e retorna esse objeto, já povoado com os dados de simulação. Essa função é decorada com pytest.fixture, com um argumento scope que define que ela é executada por módulo. Ou seja, para todos os testes que usam essa fixture e que estão definidos nesse módulo (script), o modelo só é executado uma vez e passa o seu estado para todos os testes. O primeiro teste mostrado repete a lógica do exemplo da seção anterior; o segundo é outro exemplo onde quero testar que uma função que retorna uma Series tem de fato todos os registros. Essa função é decorada com pytest.mark.parametrize, onde especifico que o parâmetro resultda função de teste assume cada um dos valores especificados na lista. Quando é invocado, pytest faz o loop automaticamente, chamando esse teste tantas vezes quantos são os elementos da lista que define o parâmetro.
Conclusões
Leitores podem estar confusos com a quantidade de informações técnicas. Peço desculpas (mas não muitas); esse post foi a melhor maneira que eu encontrei para consolidar todo meu aprendizado recente no assunto.
Nunca tinha parado para reparar como os livros na minha mesa refletem quem eu sou profissionalmente: eu sou um Engenheiro Mecânico, que estuda eletromagnetismo, publica seus estudos em LaTeX, e gosta mesmo de programar em Python o dia todo.
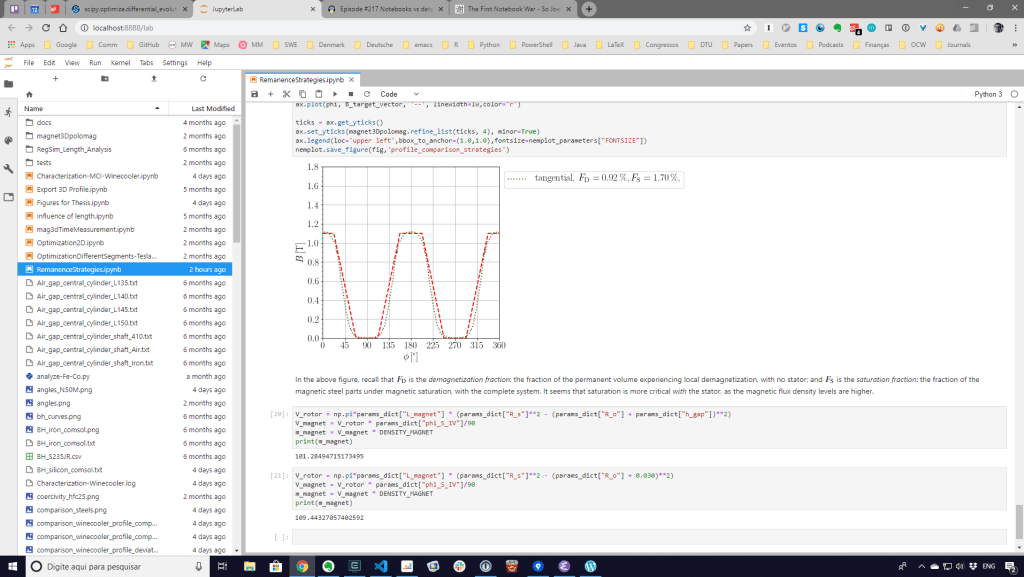
Um dia de trabalho típico (e um bom dia): programando em Python e plotando coisas no PyCharm.
A propósito: em 2018 eu finalmente parei de ser teimoso com a mentalidade de “uso apenas um editor de texto” ou “vou criar uns gráficos rápidos em Jupyter” para minhas tarefas que exigem programação. O PyCharm é fantástico para o meu fluxo de trabalho: lidando com módulos grandes, navegando entre classes e funções, executando scripts de pós-processamento. E eles oferecem gratuitamente licenças acadêmicas!