Preciso ainda falar que acredito muito em usar ferramentas computacionais dentro da sala de aula para resolver problemas reais de engenharia?
A minha linguagem de programação é Python, simplesmente porque venho usando há mais de 10 anos (!). Entretanto, algumas bibliotecas são essenciais para o tipo de trabalho que faço, e todas ou já estão disponíveis ou são facilmente instaláveis no pacote Anaconda (pesquise pela documentação sobre como instalá-las):
NumPy – para trabalhar com arrays e matrizes, como ao resolver sistemas de equações lineares
SimPy – para algoritmos de “Cálculo Numérico”: achar raízes e pontos de ótimo, integração numérica, funções especiais (e.g. funções de Bessel, bastante usadas em Transferência de Calor)
pandas – para ler arquivos em tabelas e manipular; é basicamente a funcionalidade do Excel em Python
PYroMat – idem acima, mas especificamente para modelos de gases ideais (e propriedades mais relevantes para análise de reações de combustão)
Matplotlib – para gerar gráficos de todas as análises que você vai fazer usando as ferramentas acima
Essas são o conjunto mínimo viável; se você é estudante de Engenharia Mecânica, deve aprender agora a utilizá-las, e o YouTube está cheio de tutoriais (eu aprendi basicamente lendo as documentações e pesquisando como resolver os erros que apareciam).
Como um bônus, vale a pena começar a mergulhar em scikit-learn e estudar um pouco de Aprendizado de Máquina.
Hoje eu sou Professor de Engenharia Mecânica, mas eu lembro de uma época em que eu fui aluno; e desde aquele época, uma das coisas que mais me irrita ouvir é variações do tema:
A Engenharia de hoje é toda computadorizada; devemos eliminar as aulas de Cálculo e Álgebra Linear no currículo, que são inúteis, para dar lugar a disciplinas mais avançadas!
Alguém que geralmente foi mal em Cálculo
Não me leve a mal: Cálculo e Álgebra Linear não são disciplinas fáceis ou agradáveis, e tenho colegas que de fato foram mal nestas aulas e hoje são engenheiros e engenheiras de respeito. Mas isso não serve de evidência para o argumento acima.
A Engenharia é resolver problemas práticos da sociedade com baixo custo e baixo impacto ambiental. Considere o objetivo de movimentar cargas e pessoas em automóveis motorizados: um problema prático é reduzir as emissões de poluentes de monóxido de carbono e hidrocarbonetos, compostos tóxicos. O que acontece é um balanço de efeitos: quanto menos ar, mais compostos se formam pela combustão incompleta – mas ao mesmo tempo, se há ar demais e combustível de menos, o ar vai absorver energia da combustão, abaixar a temperatura e também vai ocasionar combustão incompleta. Quando se tem um fenômeno que resulta de uma soma de efeitos, esse problema pode ser modelado por equações diferenciais. Saber resolver esse tipo de equação não é um item em uma lista de exercícios; é uma questão de estimar, e então tentar reduzir, as emissões de gases tóxicos.
Em A Mind at Play, Jimmy Soni e Rob Goodman falam dos primórdios da computação, que era à base de computadores mecânicos, analógicos, e não digitais. E o que esses diferentes computadores faziam era resolver diferentes classes de equações diferenciais. Algo que aprendi com o livro, por exemplo, era que Lord Kelvin, famoso pela sua escala de temperatura, também trabalhou no final do século XIX em um analisador harmônico, que conseguia prever, com muita precisão, o movimento das marés em um dos portos britânicos, a partir de dados passados. Deixe-me ser claro: você usava um lápis conectado na máquina para desenhar um gráfico das marés em um mês, girava manualmente algumas engrenagens, e o aparelho desenhava (após algumas horas) um outro gráfico prevendo as marés no mês seguinte – e geralmente acertava. Isto é, literalmente, aprendizado de máquina.
Essa playlist sensacional explica um outro tipo de analisador harmônico:
Agora imagine Lord Kelvin, um dos pioneiros da computação analógica, se queixando de ter de estudar cálculo.
Eu sei o que o leitor vai dizer em seguida: “mas eu não estou interessado em construir uma máquina ou desenvolver um software, só quero fazer simulações em um programa já pronto”!
Eu fiz muito disso em meu doutorado. Simulei o campo magnético de ímãs, usando um programa pronto (que, adivinhe, resolvia equações diferenciais), e comecei a notar alguns resultados estranhos. Quando você faz uma simulação computacional, você começa com uma malha (um conjunto de pontos) bem grosseira e, à medida que você vai adicionando pontos, a simulação vai ficando melhor, até uma hora que adicionar mais e mais pontos não muda o resultado final e só toma mais tempo de computação; isso é o sinal de que a malha está fina o suficiente. No meu caso: eu notei que, nos cantos dos ímãs, quanto mais e mais pontos eu adiciona, pior ficava o resultado, sem nunca estabilizar. O que está acontecendo?
Foi só quando eu parei para analisar as equações diferenciais, e estudar a teoria por trás do programa, foi que eu aprendi que isso era esperado, e o programa de fato não conseguiria simular os cantos.
Outro exemplo do meu doutorado, dessa vez simulando o escoamento de água em um trocador de calor. O programa me forneceu uma planilha de resultados, com os dados de velocidade em cada seção do trocador; ele simplesmente resolveu as equações diferenciais adequadas. Mas quando parei para analisar os resultados, notei algo estranho: a massa não se conservava. O trocador tinha uma entrada e uma saída, mas eu, sem muito conhecimento do programa que estava utilizando, digitei de forma errada os parâmetros; era como se a equação diferencial tivesse uma segunda saída de água, que estava sumindo dos cálculos. Novamente, foi quando parei para analisar as equações diferenciais, que vi o problema.
Esses exemplos não são abstratos. O ímã e o trocador de calor foram fabricados e instalados em um sistema real, custando dinheiro de verdade para fazer isso – e foi o exame minucioso da teoria, por parte dos meus colegas e de mim, que preveniu grandes erros de engenharia.
Assim, deixe-me dar um conselho: quanto mais Cálculo a leitora souber, melhor engenheira vai ser. Tudo bem, eu concordo que você não vai resolver equações diferenciais à mão como fazia nas aulas, e um computador (agora, digital) vai fazer isso para você. Mas é o conhecimento implícito, que se imprimiu no seu subconsciente, que vai lhe permitir analisar dados e detectar erros e oportunidades de melhoria.
Eu estou falando de Engenharia porque é o que eu conheço, mas posso facilmente imaginar a importância de médicos conhecerem bem biologia, ou psicólogas mergulharem fundo na filosofia.
Calouros e calouras: não menosprezem as fases iniciais. Vai valer a pena depois. Você sonha em trabalhar com Aprendizado de Máquina? Pergunte a alguém que trabalha na área o quanto de Álgebra Linear é necessário – e depois comente aqui.
Eu venho explorando o tópico de aprendizado de máquina aqui, e hoje gostaria de relatar um experimento, para ilustrar o que pode ser feito.
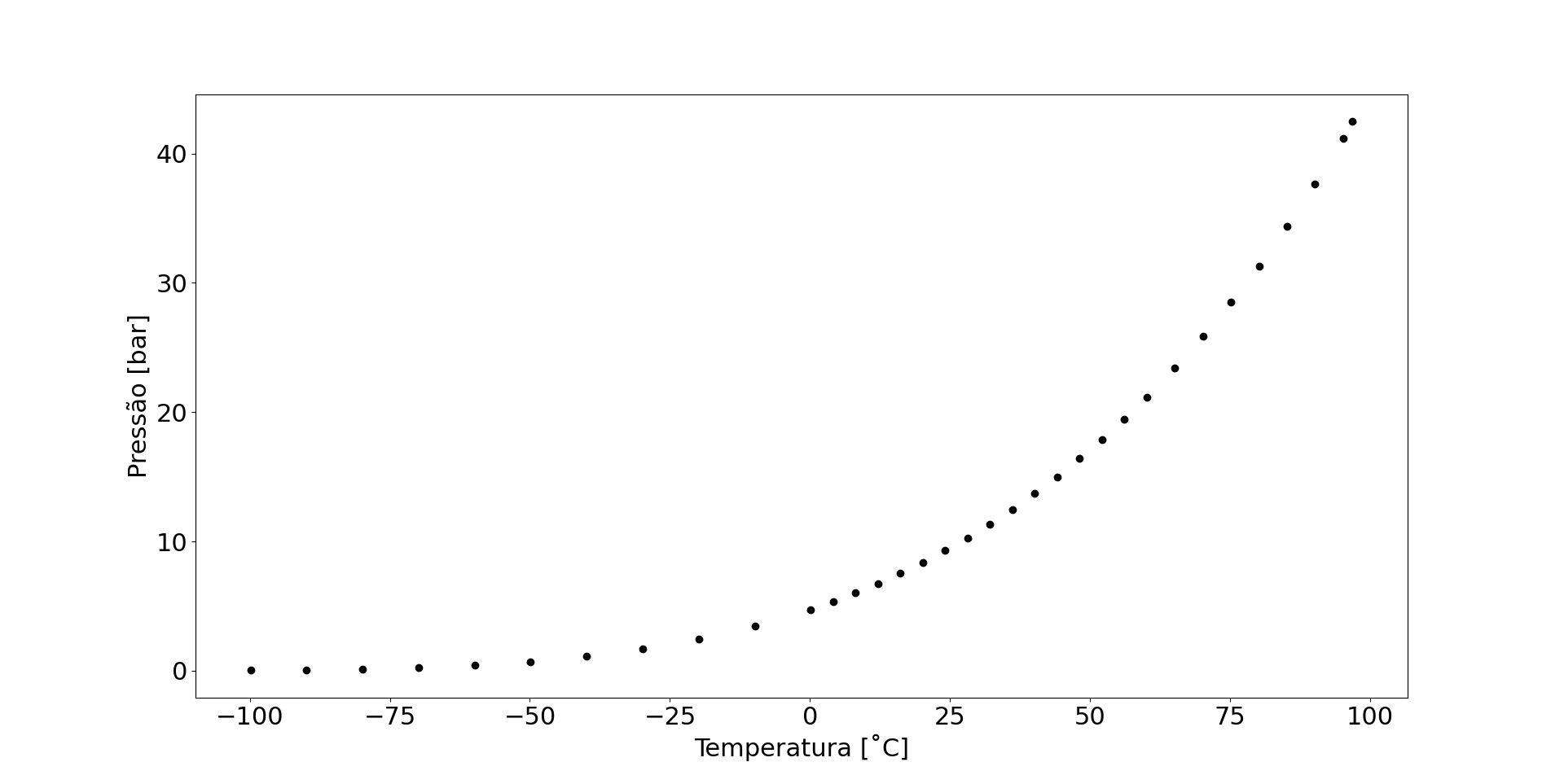
O propano é um hidrocarboneto que é usado, entre várias aplicações, como fluido refrigerante (“gás de geladeira”). Nos cálculos desse tipo de sistema, uma tarefa básica é, sabendo a temperatura, calcular a pressão que o fluido está quando saturado (isto é, quando o líquido está em equilíbrio com o vapor, que é o que acontece na maior parte da tubulação de uma geladeira).
Pois bem, eu peguei dados de temperatura e pressão de [1]:
Imagine que queremos achar a pressão para vários pontos de temperatura. Ler essas informações nesse gráfico é chato e nada preciso, assim como seria procurar em uma tabela como a que eu usei para construir esse gráfico (principalmente para números que não aparecem diretamente, como uma temperatura de 0,2 ˚C). Outra alternativa é usar programas que resolvem equações de estado, mas isto costuma demorar bastante.
Com Aprendizado de Máquina, tentamos montar expressões matematicamente simples que simbolizam a relação entre as variáveis de interesse.
Em engenharia, sempre que possível, é bom tentar achar uma relação linear entre as grandezas que estamos estudando. Isso não parece ser verdade, nesse caso; mas podemos fazer duas transformações:
Vamos tomar o inverso da temperatura, e expresso em K
Vamos tomar o logaritmo da pressão normalizada em relação a uma pressão de referência de 1 bar
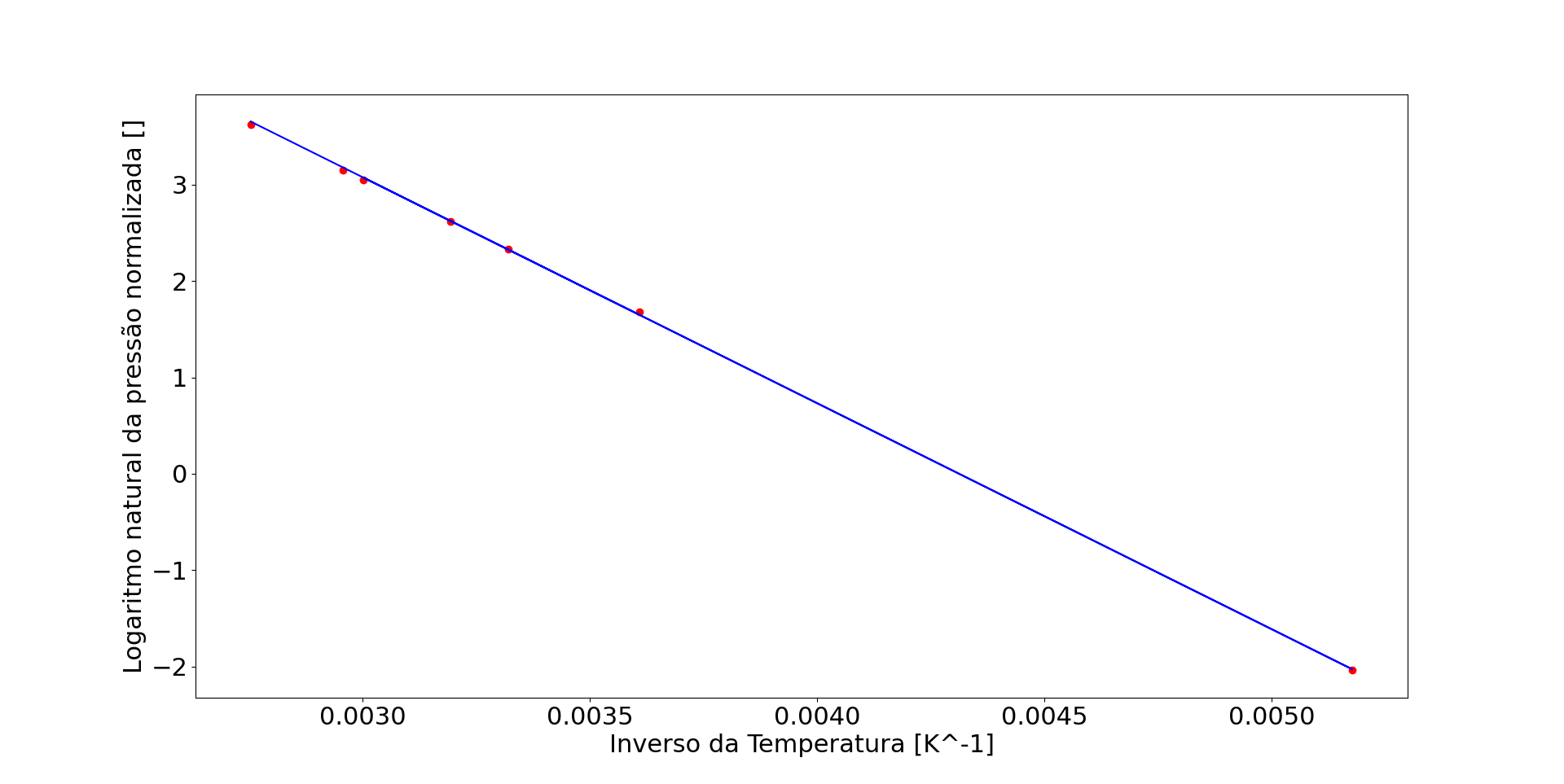
Ótimo! Parece que existe uma relação linear!
Agora vamos fazer um seguinte: vamos pegar uma parte desses pontos, e usar para treinar um modelo linear:
Os pontos em vermelho são as observações individuais retiradas da tabela; a linha em azul é uma reta que melhor representa todos os pontos
Os nossos dados parecem se ajustar bem à equação
ln (P[bar]) = -2345,6436/T[K] + 10,1146
Como falei, essa equação foi construída com um conjunto de dados (o conjunto de treinamento). Será que essa equação consegue prever os dados que não foram usados para gerar o modelo (o conjunto de teste)?
E assim, temos um modelo algébrico, definido em termos de funções simples, que consegue prever a nossa relação pressão e temperatura. Calcular a pressão com a equação acima é muito mais rápido que ler em tabelas ou usar equações de estado.
A imagem deste post não é apenas uma brincadeirinha; com aprendizado de máquina, eu consigo aprender muito sobre termodinâmica, propriedades, diferenças entre fluidos.
Deixem nos comentários se quiserem um post de follow-up, mostrando mais do código e da teoria por trás disso!
[1] Moran, Michael J; Shapiro, Howard N. Fundamentals of Engineering Thermodynamics (5 ed.). Chichester: Wiley, 2006.
Eu acabei de ganhar um prêmio por um trabalho que apresentei sobre Aprendizado de Máquina (Machine Learning), então eu deveria ser um especialista no assunto. Eu não sou, mas vou introduzir aqui o que penso sobre o assunto, como tenho aprendido, e como tenho usado na minha vida de Professor de Engenharia Mecânica.
Vamos ser francos: Aprendizado de Máquina é um termo científico que foi sequestrado por estratégias de marketing (o que em si não é ruim, pois – surpresa – cientistas gostam de ganhar dinheiro) e perdeu muito do seu signficado (o que é ruim). Como assim, máquinas aprendem? Isso significa que os robôs vão dominar o mundo? Todas as profissões estão fadadas à extinção?
Como aprendemos? Basicamente, treinamos um conceito, um método ou abordagem e testamos nossa abordagem com algum valor dito verdadeiro – na vida acadêmica, o gabarito da lista de exercícios; na vida real, comparamos com documentos históricos ou dados experimentais. Se erramos, precisamos corrigir nosso método e repetir.
Vamos pegar um exemplo que está na minha cabeça por causa das minhas aulas: desempenho de combustíveis. Um litro de gasolina libera mais energia, chamada de poder calorífico, que um um litro de etanol – não à toa, ela é mais cara. Mas o que exatamente provoca essa diferença? É porque a gasolina tem uma cor e o etanol outro? A gasolina vem do petróleo e o etanol da cana-de-açúcar?
Observando a estrutura química, eu proponho um modelo, uma tentativa de representação da realidade: o etanol tem mais oxigênio dissolvido que a gasolina (e isso pode ser verificado experimentalmente), então eu digo que o poder calorífico diminui com a presença de oxigênio no combustível.
Como posso testar isso? Uma abordagem simples seria pegar uma série de combustíveis, e separar em dois grupos: os que tem oxigênio e os que não tem. Vou fazer experimentos e medir o poder calorífico. Para cada par de combustível, um oxigenado e o outro não, o combustível com oxigênio tem de ser mais fraco que o outro. Se isso for verdade, eu aprendi um fato sobre combustíveis. Se não, tenho de propor outro modelo.
Um computador não pode olhar uma série de dados sobre combustíveis e adivinhar que os combustíveis oxigenados são mais fracos que os não-oxigenados, mas ele pode sistematicamente investigar essa hipótese; um computador pode facilmente ler um banco de dados de composição de combustíveis e fazer os cálculos. Ele pode ser programado também para testar uma enormidade de número de modelos, comparando todas as propriedades conhecidas dos combustíveis até descobrir qual a mais relevante para o poder calorífico. Importantemente, você pode alimentar o modelo com mais e mais dados de combustíveis, e não precisa re-programar o computador; ele refaz os cálculos automaticamente.
A ideia original, porém, foi minha. Em último grau, aprendizado de máquina é o meu aprendizado.
Eu comecei a estudar esse assunto quando um colega o introduziu no nosso grupo de pesquisa, baseado nos cursos que ele estava fazendo na época. Uma ideia que começou como uma “brincadeira” virou um trabalho premiado (que em breve vai virar um artigo publicado em um periódico importante). Assim é a ciência.
Como isso me afeta? Eu não sou Cientista da Computação, nem mesmo Cientista de Dados; sou Professor de Engenharia Mecânica. Para o semestre 2021-2 que se aproxima, meu objetivo principal é aplicar os conceitos de Aprendizado de Máquina em problemas reais, importantes de Engenharia Mecânica.
Engenheiros Mecânicos (e mesmo de outras áreas; eu estou falando dessa por ser a de mais afinidade para mim) lidam com dados o tempo todo. Em particular, nós precisamos lidar com catálogos de equipamentos o tempo todo; o que nós podemos aprender com esses dados? Se eu tenho dois catálogos de compressores na minha frente, como posso extrair dos dois o conhecimento de qual vai resultar num sistema mais eficiente?
Outra fonte importante de dados: tabelas de propriedades termofísicas. Eu realmente preciso parar de resolver exercícios interpolando valores nessa tabela à mão, e pensar mais sobre modelos. Como exatamente a condutividade térmica da água varia com a temperatura? Ela cresce ou diminui? Linearmente ou não?
Vou tentar documentar aqui os meus desenvolvimentos nessa área. As leitoras e leitores trabalham com Aprendizado de Máquina, e/ou querem aprender mais sobre o assunto?