Como muitas de minhas ideias, está começou com um podcast, e especificamente sobre minha mais recente obsessão: ciência de dados.
A situação: tenho um modelo numérico que simula algum problema físico. Para um mesmo modelo, é possível fazer várias análises: com e sem alguma característica, modificando ou não alguma das equações governantes do problema. O problema: como organizar todas essas análises?
Para meu deleite acadêmico, esse episódio de Talk Python to Me referenciou alguns artigos científicos, e desde então tenho testado as soluções que cientistas antes de mim já procuraram implementar para o mesmo problema.
A pasta results
Quando vou testar alguma próxima modificação no meu modelo ou analisar a influência particular de algum parâmetro , onde vou armazenar todos os resultados, de maneira a poder referencia-los depois?
O meu modelo está encapsulado numa pasta no meu computador:

A pasta raiz tem imagens, um arquivo de sumário README, alguns arquivos de dados, arquivos de suporte para Python, e diversas subpastas:
- Já falei anteriormente sobre testes, e eles estão devidamente organizados. O programa de testes que uso,
pytest, cria uma pasta de cache, que aparece no topo da lista. - A pasta
srccontém o código fonte (neste caso, em Python). Kenneth Reitz havia me convencido de que uma pasta assim deve ter o mesmo nome da biblioteca sendo desenvolvida (neste caso,magnet3Dpolomag, como aparece em outro post), mas estes artigos me convenceram de que afinal é melhor ter uma pasta chamadasrc(de source code), e suas bibliotecas dentro dessa pasta, para melhor execução de testes. Os artigos científicos citados no começo deste posts também recomendam uma pasta genéricasrc. docscontém um protótipo de documentação.vscodecontém arquivos de configuração do Visual Studio Code- e
resultsé onde a mágica acontece.
A pasta results é um repositório de todos os resultados que esse modelo já gerou. Respondendo à pergunta anterior: quando quero fazer uma nova análise, o primeiro passo é criar uma nova subpasta dentro de results:

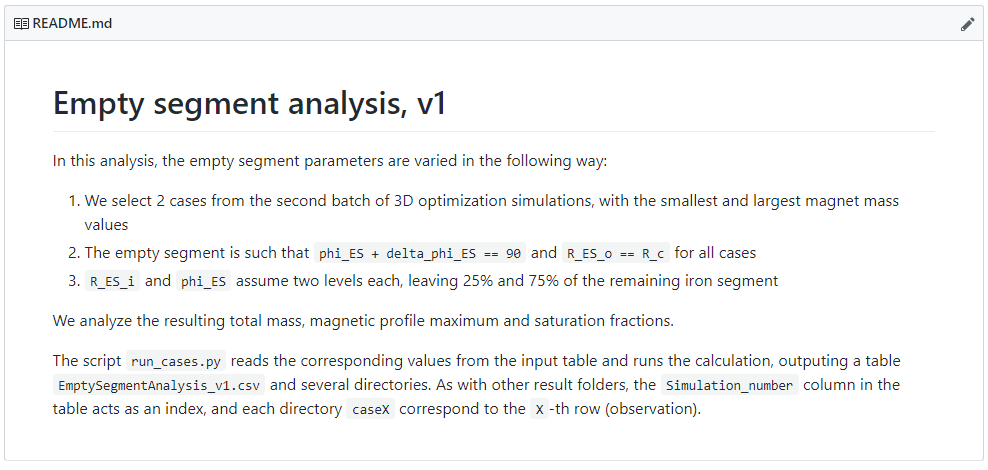
Um ponto importante dessa minha estratégia é fazer uso da interface web do GitHub, como visto acima, serve como referência online. Nas reuniões do nosso grupo de pesquisa, tenho compartilhado links para cada uma dessa subpastas junto com capturas de tela como essa, para mostrar em que estado minha pesquisa está e o que foi feito em um período. Seguindo a recomendação dos artigos citados, ponho a data no início do nome da pasta para uma ordenação temporal e para ter ideia de quando uma análise foi feita.
Cada pasta dessa armazena scripts para cálculo e processamento de dados, imagens e tabelas salvas, arquivos de referência — tudo que ajuda uma pessoa de fora (ou meu futuro eu) a entender uma parte da pesquisa usando meu modelo.

Numa organização dessa, é crucial criar um README bem feito, para evitar a confusão de abrir uma pasta cheia de arquivos soltos sem nenhuma explicação. Usando a interface web do GitHub, o README é renderizado quando se abre uma pasta, o que é muito interessante.
Conclusões
É assim que organizo minhas simulações numéricas. Ainda estou aprendendo a implementar esse método, mas ele tem me dado bastante tranquilidade, permite-me facilmente achar análises passadas, e elimina a dúvida de “por onde começar”, ao testar algo novo nos meus modelos numéricos.
Esse é um assunto que me interessa muito. Os leitores têm alguma dica?
